From the Item Bank |
||
The Professional Testing Blog |
||
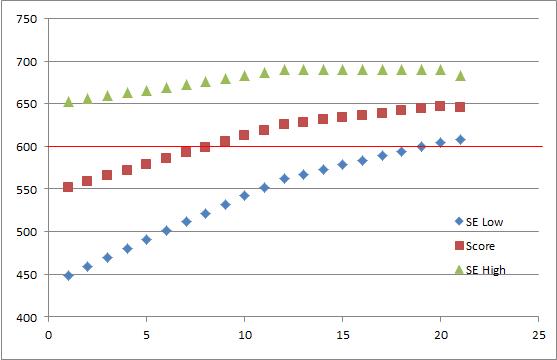
Computer Adaptive Testing: An Overview and ConsiderationsJune 24, 2015 | |Computer Adaptive Testing (CAT) is a testing methodology that weds two processes—adaptive testing and computer administration—for efficient measurement and administration. When compared to fixed length exams delivered linearly on a computer, CAT exams measure a candidate’s ability with fewer delivered exam questions and higher precision. By precision, it is suggested that error is reduced and reliability is increased. What allows us to adapt tests to match candidate ability? Pairing items with people is done by using Item Response Theory. Item Response Theory (IRT) is a modern measurement theory that allows for the development of exams that match item difficulty to a candidate’s ability. For CAT to adapt to a candidate’s ability, there are item selection algorithms. These algorithms include estimating candidate ability, matching items delivered to candidate’s ability, preventing over exposure of items, and matching item delivery with the exam blueprint or content requirements. Because of this, large item pools are needed to assure exams can be delivered to meet all ability levels across all content areas. One advantage that can be seen with IRT-based CAT is more reliable exam scores which results in a higher confidence in the pass/fail consistency estimates. With credentialing exams, the primary reliability estimates we seek are those associated with making consistent pass/fail decisions. A second possible advantage is the reduction in exam administration time. As a real-life example, a two day paper exam with limited exam sites was reduced to an exam that can be taken in one sitting. In addition, the number of exam sites grew exponentially allowing candidates to register within an exam date window and take the exam closer to their location. As one could imagine, the benefits of this transition were significant. Example In the example below, a CAT was administered and the pass/fail decision was reached in 23 items. The cut-score was 600 on a scale range of 0 to 1000. There are 3 data points for each item. The lower Standard Error (SE Low), the observed score (Score), and higher Standard Error (SE High). In essence this is a confidence interval. Within this band, we can be highly confident where the person’s true score resides. The stopping rule for this was having the entire confidence band on one side of the passing score.
As can be seen, with each item administered, the error band is reduced. With each item completed, the process selects the next item to minimize error and match the item’s difficulty with the candidate’s ability. Because of this, a candidate’s proficiency can be identified with fewer items. While CAT is a very attractive option for programs, it requires a very robust item bank which can increase expenses. There is also a requirement for moderate to large testing samples (number of candidates taking the exam). CAT is an attractive solution for robust exam programs that have lengthy tests. A large number of candidates are required for the IRT calibrations, but the shorter exam seat time can result in large cost savings. Categorized in: Industry News |
||

Comments are closed here.